Compilers, optimizers, assembly and other scary things
I recently gave a talk at the maths department informal computing seminar (link) on using the optimizers built into compilers to give a significant performance increase in code.

The idea behind the talk came from talking to a friend who knew just enough programming to do his work, but had little idea of the power hiding in his compiler. When I suggested turning the optimisers on his code performed around 10 times fast with no extra work.
-O3 -march=native when
compiling C++. This allows the compiler to do lots of clever things to speed up
your code.
The code used as examples throughout is available on Github.
A compiler is like a big black box, which takes human readable code and outputs a binary file for the computer to run. Here we will be looking at some assembly, which is an approximation of the machine code and gives some idea of what your processor will actually be doing to compute what you asked it to.
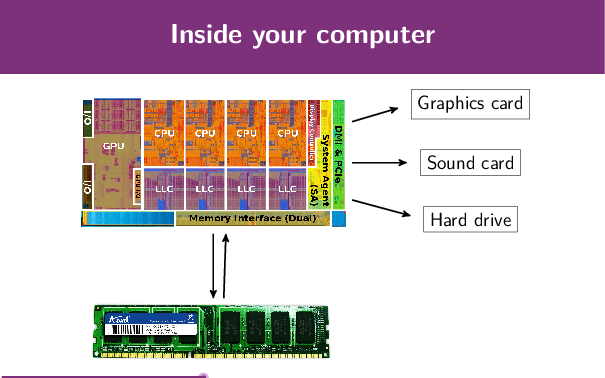
A modern CPU includes much more than just a number of computational cores, they can also include graphics processors, memory controllers and other buses to talk to any peripherals attached to the computer. However, when we look at optimising code we are really only looking at the small area of the processor dedicated to computations and data handling.

An important idea when looking at assembly is where data is stored. Each CPU core has a number of registers, where maths and other operations can be performed and where data can be stored with near instant access. Further out, the CPU has a number of different caches for storing data, with data access in L1 taking just a couple of nanoseconds, L2 roughly 10ns and L3 around 50ns. Any data which is too big for caches end up in RAM or failing that the hard drive - both of which are significantly slower than the cached store.

Assembly uses the registers directly, with various ways of accessing them and
the data in them. A 64 bit processor can pretend that any of its registers are
64 or 32 bits long, and differentiates between the two in assembly by using
either an r or an e prefix.
Here I use the Intel assembly syntax, where results of operations are stored in
the first parameter, so add eax, edi adds the value of register edi to the
value of eax and stores the result in eax. Similarly mov eax, DWORD PTR
[ptr] moves the value of the data at address ptr into the register eax.
A simple swapping example

So how about a short example? In a job interview a couple of years ago, I was
asked to write a short function to swap the values of two ints. This can be done
in a few ways, and in fact the C++ standard library has an easy way to do this
using std::swap.
The most common way of doing this is using a temporary variable, which without any optimisations produces the following assembly (in gcc version 6.2):
void swap(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
} push rbp
mov rbp, rsp
mov QWORD PTR [rbp-24], rdi
mov QWORD PTR [rbp-32], rsi
mov rax, QWORD PTR [rbp-24]
mov eax, DWORD PTR [rax]
mov DWORD PTR [rbp-4], eax
mov rax, QWORD PTR [rbp-32]
mov edx, DWORD PTR [rax]
mov rax, QWORD PTR [rbp-24]
mov DWORD PTR [rax], edx
mov rax, QWORD PTR [rbp-32]
mov edx, DWORD PTR [rbp-4]
mov DWORD PTR [rax], edx
nop
pop rbp
ret
This code does a lot stuff for such a simple function. It starts off with the
address of a in rdi, which gets copied onto the stack (mov QWORD PTR
[rbp-24], rdi), then this address which was just written in copied back out into
rax (mov rax, QWORD PTR [rbp-24]) before the value of a is read into eax
(mov eax, DWORD PTR [rax]). This copying data around is really unnecessary and
could be much more efficiently computed as mov eax, DWORD PTR [rdi], but the
compiler defaults to doing exactly what the code tells it.
If we now turn on the first level of optimisers, so compile with gcc -O1, we
get the much nicer assembly:
mov eax, DWORD PTR [rdi]
mov edx, DWORD PTR [rsi]
mov DWORD PTR [rdi], edx
mov DWORD PTR [rsi], eax
ret
Which avoids the pointless copying and simply loads both a and b into
registers before copying them back out into memory. Note that although the code
specifies the use of a third temporary integer, this never really exists outside
the CPU registers.
Other ways of swapping integers include using maths and using bitwise operations:
void swap_tmp(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
void swap_add(int& a, int& b) {
a += b;
b = a - b;
a -= b;
}
void swap_xor(int& a, int& b) {
a ^= b;
b ^= a;
a ^= b;
}swap_tmp(int&, int&):
mov eax, DWORD PTR [rdi]
mov edx, DWORD PTR [rsi]
mov DWORD PTR [rdi], edx
mov DWORD PTR [rsi], eax
ret
swap_add(int&, int&):
mov eax, DWORD PTR [rsi]
add eax, DWORD PTR [rdi]
mov DWORD PTR [rdi], eax
sub eax, DWORD PTR [rsi]
mov DWORD PTR [rsi], eax
sub DWORD PTR [rdi], eax
ret
swap_xor(int&, int&):
mov eax, DWORD PTR [rdi]
xor eax, DWORD PTR [rsi]
mov DWORD PTR [rdi], eax
xor eax, DWORD PTR [rsi]
mov DWORD PTR [rsi], eax
xor DWORD PTR [rdi], eax
ret
These other options do not use the temporary variable, so on the face of it look
to be more efficient with memory, in stead using more complicated operations.
However, when you look at the (optimised) assembly you can see that all the
functions have to move the values of a and b into registers - so it really
comes down to whether it is faster to do 4 moves, 3 moves, an add and 2
subtractions, or 3 moves and 3 xors.
This is where benchmarks come in:
Benchmark Time CPU Iterations
---------------------------------------------------------------
BM_tmp/12.0557k/96.4502k 2 ns 2 ns 354633381
BM_add/12.0557k/96.4502k 4 ns 4 ns 171276756
BM_xor/12.0557k/96.4502k 4 ns 4 ns 172356265
The swap functions using the more complicated instructions take longer. (Note that there is also a problem in this example where swap_tmp is inlined before the other two functions, which might also contribute to this result.)
However, when the optimiser is turned up even more, and the code is compiled
with gcc -O2, all the functions are inlined, and perform the same:
Benchmark Time CPU Iterations
---------------------------------------------------------------
BM_tmp/12.0557k/96.4502k 2 ns 2 ns 382471464
BM_add/12.0557k/96.4502k 2 ns 2 ns 384323398
BM_xor/12.0557k/96.4502k 2 ns 2 ns 384266620
To see what is really going on, we need to allow our swap functions to be inlined and compare the assembly in this case.
int main(int argc, char**) {
int a = 0;
int b = 1;
for(int i = 0; i < argc; ++i) {
swap_???(a,b);
}
return a - b;
}Because we want to see how the code behaves when optimised, we need to trick the compiler into optimising the swap function, but not optimising so well that it realises we’re not really doing anything in the function. We use the for-loop and return statement to help trick the compiler, and we get the following:
main:
test edi, edi
jle .L7
mov eax, 1
mov ecx, 0
mov edx, 0
jmp .L6
.L8:
mov esi, ecx
mov ecx, eax
mov eax, esi
.L6:
add edx, 1
cmp edi, edx
jne .L8
.L5:
sub eax, ecx
ret
.L7:
mov ecx, 1
mov eax, 0
jmp .L5
main:
test edi, edi
jle .L7
mov eax, 1
xor ecx, ecx
xor edx, edx
jmp .L6
.L8:
mov esi, ecx
mov ecx, eax
mov eax, esi
.L6:
add edx, 1
cmp edi, edx
jne .L8
.L5:
sub eax, ecx
ret
.L7:
mov ecx, 1
xor eax, eax
jmp .L5
main:
xor eax, eax
test edi, edi
mov ecx, 1
jle .L5
xor edx, edx
.L6:
add edx, 1
cmp edi, edx
xchg ecx, eax
jne .L6
.L5:
sub eax, ecx
ret
It turns out the compiler generates the same code for both swap_tmp and for
swap_add where the main swapping loop occurs between the labels .L8 and
.L6, while swap_xor uses the special instruction xchg ecx, eax which swaps
the values in the two registers ecx and eax.
So this is the first lesson of compiler optimisers. Different C++ can give the same machine code, and that compiling without any optimisation will give you exactly what your code asks for, but that is usually much slower than it needs to be.
We also saw that the functions got inlined into the main function above. The
assembly shown above contains no call swap_add instuction for example. This is
another way that compilers will help to make things faster and prevent
needlessly copying data around.
Something more complicated
I also used the following function to show off how optimisers can help speed up code:
int accumulate(int *arr, int size, int initial) {
for (int i = 0; i < size; ++i) {
initial += arr[i];
}
return initial;
}Here we add up all the entries in an array of ints. This is also implemented in
the standard library, we could use std::accumulate instead. With no
optimisations, both functions are really slow, and the overhead of the iterators
used in the STL version make it even slower than just using pointers.
Benchmark Time CPU Iterations
-------------------------------------------------
BM_acc/8 22 ns 22 ns 31143589
BM_acc/64 177 ns 177 ns 3954088
BM_acc/512 1300 ns 1300 ns 517754
BM_acc/4k 10382 ns 10382 ns 67801
BM_acc/8k 20719 ns 20720 ns 33949
BM_stl/8 96 ns 96 ns 7130469
BM_stl/64 607 ns 607 ns 1141905
BM_stl/512 4581 ns 4581 ns 150918
BM_stl/4k 36573 ns 36575 ns 19148
BM_stl/8k 73335 ns 73336 ns 9197
Using either -O1 or -O2 give the same results, where the difference between
the STL version and the pointer version of the function is optimised away.
Benchmark Time CPU Iterations
-------------------------------------------------
BM_acc/8 6 ns 6 ns 97439287
BM_acc/64 40 ns 40 ns 17603626
BM_acc/512 239 ns 239 ns 2941095
BM_acc/4k 1813 ns 1813 ns 383717
BM_acc/8k 3647 ns 3647 ns 192835
BM_stl/8 7 ns 7 ns 95338644
BM_stl/64 46 ns 46 ns 15245619
BM_stl/512 244 ns 244 ns 2864652
BM_stl/4k 1815 ns 1815 ns 382999
BM_stl/8k 3650 ns 3650 ns 191629
Both these optimisation levels give the same performance, so one may assume
that’s the best you can get, but when you look at -O3, suddenly for the larger
arrays the code performs around 3.5 times faster.
Benchmark Time CPU Iterations
-------------------------------------------------
BM_acc/8 3 ns 3 ns 205595153
BM_acc/64 12 ns 12 ns 57579435
BM_acc/512 70 ns 70 ns 9717876
BM_acc/4k 487 ns 487 ns 1421876
BM_acc/8k 969 ns 969 ns 707230
BM_stl/8 4 ns 4 ns 188993456
BM_stl/64 13 ns 13 ns 55894542
BM_stl/512 72 ns 72 ns 9633159
BM_stl/4k 486 ns 486 ns 1441199
BM_stl/8k 978 ns 978 ns 705693
To see why we need to once again delve into the assembly. For the -O1 case,
the whole function is made up of 16 assembly lines and the inner loop of the
accumulate calculation looks like:
...
mov DWORD PTR [rdx], ecx
add rdx, 4
add ecx, 1
cmp rdi, rdx
jne .L12
...
Whereas in the more optimised case, the assembly has over 120 lines, with loads more complexity, jumps and comparisons. The interesting thing though is that the inner loop now looks like:
...
add ecx, 1
paddd xmm0, XMMWORD PTR [r9]
add r9, 16
cmp eax, ecx
ja .L9
...
Which uses a new instruction paddd and a different register xmm0. These are
from the SSE vector instruction set, which is a completely different part of the
CPU and are used to perform a number of the same operations at the same time.
Whereas the previous code added each integer to the total sum one by one, this
new SSE code can handle 4 integers at once. The code is a lot more complex, so
we don’t see a full 4 times speed up, but 3.5 times is still impressive.
There have been a number of advances in the vector processing units on CPUs over
the years, but the compiler will be conservative and only use the most
widespread instructions. If we also provide the -march=native flag to the
compiler, then it can use whatever your hardware supports (on the machine which
compiles the code), so if your computer can handle additions on 8 integers at
once, then adding this flag will allow the compiler to compute more stuff at the
same time.
Summary

-
The compiler is really clever and can make your code perform loads better - if you let it.
-
By default you compiler is really conservative.
-
Use
-O3 -march=nativeto get the best performance (provided you run the code on the same computer you compile on). -
The compiler is going to change things round and do things differently to how you said - so don’t worry too much.
-
Always benchmark and measure. There’s no point in carefully optimising code which only runs once.
Other links
- Jason Turner’s Introduction to assembly and all his C++ weekly videos are good watches.
- Chandler Carruth’s talk Tuning C++: Benchmarks, and CPUs, and Compilers! Oh My! inspired this presentation, and goes into much more depth about benchmarking, performance and compilers.
- The Compiler explorer is a great place to play around with assembly and see what different compilers and options give you.